Ошибки,
проявляющиеся в ходе сбора данных, могут
быть разделены на две группы
[Черчилль, с. 500]:
-
Ошибки
в выборке.
Они связаны
с несоответствие параметров изучаемой
выборки и генеральной совокупности.
Такие ошибки возникают на стадии
проектирования выборки и подробно
рассмотрены в главе 7. -
Систематические
ошибки.
В эту группу входят все
остальные ошибки, не являющиеся ошибками
выборки.
Они возникают в результате несовершенной
концепции или логики исследования,
неправильной интерпретацией ответов,
а также ошибок на стадии обработки,
анализа данных и представления
информации.
Систематические
ошибки делятся на два вида:
-
Случайные.
Такие ошибки приводят к отклонениям
от истинного значения на случайную
величину и в случайную сторону. -
Неслучайные.
Такие ошибки приводят к одностороннему
отклонению результата от истинного
значения.
Систематические
ошибки более опасны, чем ошибки в выборке:
их труднее измерить, кроме того, увеличение
выборки далеко не всегда позволяет их
сократить. Величина систематической
ошибки может в десять раз превысить
ошибку выборки и обратить результаты
исследований практически в ничто.
Систематические
ошибки могут быть сокращены.
Однако, инструментами
такого сокращения выступают
не увеличение численности выборки, а
специальные
методы.
Для того, чтобы их правильно применить,
необходимо определить основные источники
систематических ошибок.
Классификация
систематических ошибок по источникам
возникновения
представлена на
рис. 8.2.

Существует
два основных вида систематических
ошибок по источникам их возникновения
[Черчилль, с. 501 – 521]:
-
ошибка
ненаблюдения; -
ошибка
наблюдения.
Ошибка
ненаблюдения
связана с невозможностью получить
данные от части элементов исследуемой
совокупности.
Такая
ошибка может возникнуть по двум основным
причинам:
-
часть
объекта исследования не представлена
в выборке (ошибка
неохвата); -
часть
элементов выборки не представила данных
(ошибка
неполучения данных
из-за отсутствия на месте либо отказа
от интервью).
Ошибка
наблюдения
возникает при несоответствии данных
об элементах совокупности, представленных
в отчёте, истинным значениям.
Такое
несоответствие может возникнуть при
следующих
обстоятельствах:
-
предоставлении
элементами некорректных данных; -
неправильной
регистрации данных; -
ошибках
в обработке, анализе или представлении
итогов исследования.
Ошибки
неохвата
возникают вследствие недостаточно
тщательному анализу процедуры формирования
выборки.
При использовании
пропорциональных методов формирования
выборки на результаты опроса накладывают
отпечаток волевые решения полевых
сотрудников. Они склонны получать данные
от наиболее доступных им респондентов,
что приводит часто к выпадению из
исследования людей с очень низкими и
очень высокими доходами при поквартирном
обходе. При опросе по телефону могут
выпасть люди, не имеющие телефона. При
опросе в магазине выпадают те, кто редко
посещает магазины либо вообще в них не
ходит.
С ошибкой неохвата
связана ошибка
перебора,
которая возникает при попадании некоторых
элементов в выборку несколько раз.
Основная проблема
ошибки неохвата заключается в том, что
для её оценки необходимо иметь некие
независимые внешние показатели по
исследуемой совокупности, с которыми
можно сопоставить результаты проведённого
исследования
(например, результатов переписи или
другого надёжного исследования, не
утратившие своей актуальности). При
наличии таких независимых достоверных
данных, исследователь должен заранее
определить вид собираемых данных для
того, чтобы их можно было сопоставить
с независимым источником.
Основным методом
сокращения ошибок неохвата и ошибок
перебора является улучшение основы
выборки,
чтобы она охватывала все исследуемые
элементы и не допускала дублирования.
Например, для избежания ошибки перебора
каждому элементу может приписываться
весовой корректирующий коэффициент,
обратно пропорциональный вероятности
попадания указанного элемента в выборку.
Ошибка
неполучения данных
является вторым видом ошибок ненаблюдения.
Она возникает в том случае, если
исследователи не могут собрать данные
от элементов, входящих в состав выборки.
Это происходит по двум причинам:
отсутствие и отказ от интервью.
Для измерения
возможной величины этой ошибки в практике
маркетинговых исследований при опросах
применяется специальный показатель –
доля ответивших.
Доля
ответивших
– отношение количества полных интервью
к общему количеству приемлемых
респондентов в выборке.
Главным критерием
является чёткое определение требований
приемлемости применительно к исследуемой
совокупности.
Проблема
отсутствия может решаться несколькими
способами:
-
установление
предварительной договорённости о
времени контакта с респондентом
(эффективно для опроса промышленных
потребителей либо чиновников); -
повторные
попытки контакта.
Повторные попытки
контакта являются одним из самых
эффективных способов снижения ошибки
неполучения данных.
Исследователи пришли к выводу, что
исследование с небольшой выборкой, но
многократными повторными попытками
контакта предоставляют более точную
информацию, чем исследования с большой
выборкой и без повторных попыток контакта
при отсутствии респондента.
Эффективность
в решении проблемы отсутствия респондентов
разрешается путём профессиональной
подготовки полевых сотрудников
установлению контакта и процедуре
повторных попыток контакта.
Кроме
повторных попыток контактов, возможно
сократить данную ошибку, используя
статистические методы.
В таком случае у респондентов выясняют
с помощью специальных вопросов, как
часто они бывают на месте исследования
(например, дома), и, в зависимости от
этого, им присваивается весовой
коэффициент. Чем реже респондент бывает
на месте исследования, тем более высокий
весовой коэффициент он получает.
Отказ респондента
от общения может возникать по многим
причинам,
обусловленным особенностями респондентов,
организаций-исследователей, обстоятельств
контакта, темы исследований и
профессионализма интервьюера. Определённое
значение имеет метод сбора информации:
личная встреча приводит к наименьшему,
а почтовый опрос к наибольшему количеству
отказов.
Существует
три основных группы методов снижения
ошибок из-за отказа респондента от
общения:
-
Методы
повышения доли первичных ответов.
Для этого производится создание
благоприятных условий для интервью и
обучение полевого персонала. -
Повторные
попытки контакта.
Они приносят результат, если причиной
отказа респондента являются врéменные,
изменчивые условия: состояние здоровья,
настроение, усталость. В таком случае
при повторной попытке контакта респондент
может согласиться участвовать в
исследовании. -
Статистическая
коррекция результатов.
Они заключаются в придании определённых
весовых коэффициентов респондентам в
зависимости от степени сотрудничества
страты, к которой они принадлежат, с
исследователями.
Ошибки
наблюдения,
вторая группа систематических ошибок,
ещё более
сложны в оценке и контроле.
Ошибки наблюдения ещё менее заметны,
чем ошибки ненаблюдения.
Существует два
основных вида ошибок наблюдения:
-
ошибки
сбора; -
ошибки
регистрации.
Ошибки
сбора
заключаются
в предоставлении респондентом ложных
данных.
Причиной
может быть неполное соответствие трёх
групп характеристик интервьюера и
респондента
[Черчилль, 516 – 521]:
-
Личные
особенности
(возраст, образование, общественный
статус, этническая и религиозная
принадлежность, пол и другие). Чем
сильнее различаются по этим характеристикам
респондент и интервьюер, тем сильнее
недопонимание, возникающее между ними.
В этом отношении наиболее эффективным
способом снижения ошибки является
подбор личности интервьюера к каждой
группе респондентов. -
Психологические
особенности (восприятие,
позиция, намерения, мотивы). Каждый
интервьюер имеет свои психологические
особенности, которые могут повлиять
на результаты сбора данных, исказив
их. Для сокращения такой ошибки
разрабатываются детальные формальные
процедуры, которым интервьюер должен
неукоснительно следовать. -
Поведенческие
особенности.
Эти особенности интервьюера и респондента
влияют на возникновение ошибок в ходе
их взаимодействия. Ошибки возникают,
в основном, вследствие того, что
интервьюеры не придерживаются инструкций,
не могут правильно сформулировать и
уточнить вопрос, правильно записать
ответ. В некоторых случаях происходит
подтасовка данных интервьюерами.
Методом снижения ошибки в этом случае
является тщательный подбор и обучение
полевого персонала, а также последующий
контроль. Подробнее это было рассмотрено
в предыдущем параграфе.
Итак,
процедура сбора данных подвержена
влиянию множества ошибок, систематических
и ошибок выборки. Только
тщательные и действенные превентивные
меры позволяют на этом этапе обеспечить
достоверность полученных данных для
сохранения практической значимости
проекта маркетингового исследования.
Контрольные
вопросы к блоку А
-
Каковы
основные элементы процесса полевых
исследований? -
Какие
подходы существуют к осуществлению
полевых работ, в чём их преимущества и
недостатки? -
Каковы
структура полевых работ? -
Каковы
особенности отбора персонала для
полевых работ? -
Что
происходит на этапе подготовки полевого
персонала? -
Как
осуществляется контроль над работой
полевого персонала? -
Как
проверяются результаты полевых работ
и оценивается труд полевого персонала? -
Какие
ошибки возникают на этапе сбора данных? -
Что
такое ошибки в выборке и как они
возникают? -
Что
такое систематические ошибки? -
Какие
виды систематических ошибок существуют? -
Что
такое ошибка ненаблюдения и по каким
причинам она возникает? -
Что
такое ошибка наблюдения и каковы факторы
её возникновения? -
В
чём заключается ошибка неохвата и как
она может быть снижена? -
Что
такое ошибка перебора? -
Как
можно оценить ошибку неохвата? -
В
чём причина возникновения ошибки
неполучения данных? -
Для
чего используется показатель «доля
ответивших»? -
Как
разрешается проблема отсутствия
респондента на месте интервью? -
Какие
методы существуют для решения проблемы
отказа от ответа? -
Что
такое ошибка сбора, почему она возникает? -
Как
можно сократить ошибку сбора?
Блок
B
Полевые
исследования:
-
Подготовка
полевых работ
[Божук-Ковалик, с. 142 – 144; Голубков, с.
253 – 254; Малхотра, с. 500 – 507] -
Контроль
над полевыми работами
[Божук-Ковалик, с. 144 – 145; Малхотра, с.
507 – 511]
Ошибки
на этапе сбора данных:
-
Ошибки
ненаблюдения
[Малхотра, с. 454 – 462; Черчилль, с. 503 –
515]. -
Ошибки
наблюдения
[Голубков, с. 254 – 258; Черчилль, с. 515 –
521].
Контрольные
задания к блоку B
-
Составьте
инструкции для интервьюеров по проведению
полевых исследований по определённой
Вами теме среди студентов университета. -
Посетите
Интернет-сайты агентств по маркетинговым
исследованиям и составьте отчёт по
найденной информации о проведении
полевых работ. -
На
сайте Ассоциации маркетинговых
исследований США (http://www.mra—net.org)
найдите этический кодекс по маркетинговым
исследованиям, ознакомьтесь с разделом,
касающимся полевых работ. Попытайтесь
найти аналогичный документ российской
ассоциации. -
Определите
цели, задачи и методы проведения
какого-либо проекта маркетингового
исследования. Опишите детально все
возможные ошибки на этапе сбора данных
и способы их сокращения.
Блок
C
Подготовка и
проведение сбора данных.
Осуществите процедуру подготовки этапа
сбора данных: составьте программу,
определите требования к финансовым и
людским ресурсам. Определите источники
возможных ошибок ненаблюдения и
наблюдения. Выработайте мероприятия
для сокращения указанных ошибок.
Определите возможности для последующего
контроля величины указанных ошибок.
При получении соответствующего задания
от преподавателя, осуществите сбор
данных. Результаты осуществления этапа
подготовки полевых работ и сбора данных
отразите в отчёте о групповой работе.
Литература
для дальнейшего изучения
-
Божук
С.Г., Ковалик Л.Н.
Маркетинговые исследования. СПб.: Питер,
2003. -
Голубков
Е.П.
Маркетинговые исследования: теория,
методология и практика. 2-е изд. М.:
Финпресс, 2000. -
Малхотра
Н.К.
Маркетинговые исследования. Практическое
руководство, 3-е изд. М.: Вильямс, 2002. -
Черчилль
Г.А.
Маркетинговые исследования. СПб.: Питер,
2001.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Все курсы > Анализ и обработка данных > Занятие 5
На прошлом занятии, посвященном практике EDA, мы работали с «чистыми данными», то есть такими данными, в которых нет ни ошибок, ни пропущенных значений. К сожалению, так бывает далеко не всегда.
Сегодня мы научимся очищать данные от дубликатов, неверных и плохо отформатированных значений, а также исправлять ошибки в дате и времени. На следующем занятии мы поговорим про работу с пропусками.
Откроем ноутбук к этому занятию⧉
Ошибки в данных могут встречаться по многим причинам. Они могут быть связаны с человеческим фактором, например, простой невнимательностью, или вызваны сбоями в работе записывающего какие-либо показатели оборудования.
В качестве примера мы будем использовать несложный датасет, в котором содержатся данные за 2019 год об отдельных финансовых показателях сети магазинов одежды, представленной в нескольких городах мира. В частности, нам доступна следующая информация:
- month — за какой месяц сделана запись
- profit — прибыль (profit) по сети
- MoM — изменение выручки (revenue) сети по отношению к предыдущему месяцу
- high — магазин с наибольшей маржинальностью (margin) продаж
Создадим датафрейм из словаря.
|
financials = pd.DataFrame({‘month’ : [’01/01/2019′, ’01/02/2019′, ’01/03/2019′, ’01/03/2019′, ’01/04/2019′, ’01/05/2019′, ’01/06/2019′, ’01/07/2019′, ’01/08/2019′, ’01/09/2019′, ’01/10/2019′, ’01/11/2019′, ’01/12/2019′, ’01/12/2019′], ‘profit’ : [‘1.20$’, ‘1.30$’, ‘1.25$’, ‘1.25$’, ‘1.27$’, ‘1.11$’, ‘1.23$’, ‘1.20$’, ‘1.31$’, ‘1.24$’, ‘1.18$’, ‘1.17$’, ‘1.23$’, ‘1.23$’], ‘MoM’ : [0.03, —0.02, 0.01, 0.02, —0.01, —0.015, 0.017, 0.04, 0.02, 0.01, 0.00, —0.01, 2.00, 2.00], ‘high’ : [‘Dubai’, ‘Paris’, ‘singapour’, ‘singapour’, ‘moscow’, ‘Paris’, ‘Madrid’, ‘moscow’, ‘london’, ‘london’, ‘Moscow’, ‘Rome’, ‘madrid’, ‘madrid’] }) financials |
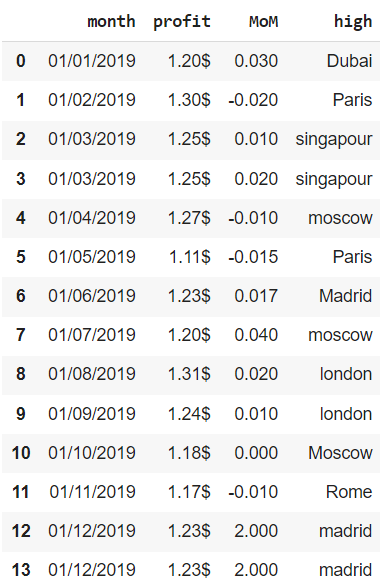
Воспользуемся методом .info() для получения общей информации о датасете.
|
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 14 entries, 0 to 13 Data columns (total 4 columns): # Column Non-Null Count Dtype — —— ————— —— 0 month 14 non-null object 1 profit 14 non-null object 2 MoM 14 non-null float64 3 high 14 non-null object dtypes: float64(1), object(3) memory usage: 576.0+ bytes |
Перейдем к поиску ошибок в данных.
Дубликаты
Поиск дубликатов
Заметим, что хотя данные представлены за 12 месяцев, в датафрейме тем не менее содержится 14 значений. Это заставляет задуматься о дубликатах (duplicates) или повторяющихся значениях. Воспользуемся методом .duplicated(). На выходе мы получим логический массив, в котором повторяющееся значение обозначено как True.
|
# keep = ‘first’ (параметр по умолчанию) # помечает как дубликат (True) ВТОРОЕ повторяющееся значение financials.duplicated(keep = ‘first’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# keep = ‘last’ соответственно считает дубликатом ПЕРВОЕ повторяющееся значение financials.duplicated(keep = ‘last’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 True 13 False dtype: bool |
Результат метода .duplicated() можно использовать как фильтр.
|
# с параметром keep = ‘last’ будет выведено наблюдение с индексом 12 financials[financials.duplicated(keep = ‘last’)] |

Также заметим, что если смотреть по месяцам, у нас две дублирующихся записи, а не одна. В частности, повторяется запись не только за декабрь, но и за март. Проверим это с помощью параметра subset.
|
# с помощью параметра subset мы ищем дубликаты по конкретным столбцам financials.duplicated(subset = [‘month’]) |
|
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# посчитаем количество дубликатов по столбцу month financials.duplicated(subset = [‘month’]).sum() |
Создадим новый фильтр и выведем дубликаты по месяцам.
|
# укажем параметр keep = ‘last’, больше доверяя, таким образом, # последнему записанному за конкретный месяц значению financials[financials.duplicated(subset = [‘month’], keep = ‘last’)] |

Аналогичным образом мы можем посмотреть на неповторяющиеся значения.
|
( ~ financials.duplicated(subset = [‘month’])).sum() |
Этот логический массив можно также использовать как фильтр.
|
financials[ ~ financials.duplicated(subset = [‘month’], keep = ‘last’)] |
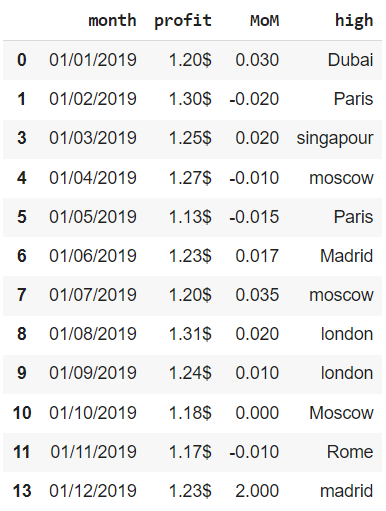
Обратите внимание, индекс остался прежним (из него просто выпали наблюдения 2 и 12). Мы исправим эту неточность при удалении дубликатов.
Удаление дубликатов
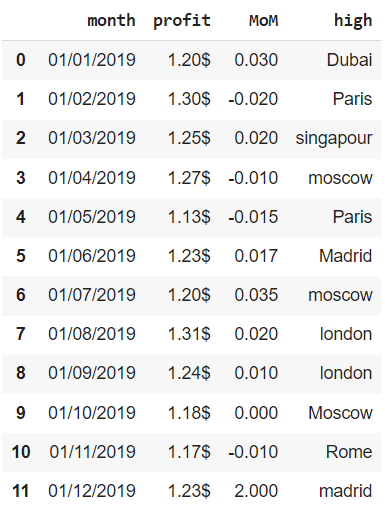
Метод .drop_duplicates() удаляет дубликаты из датафрейма и, по сути, принимает те же параметры, что и метод .duplicated().
|
# параметр ignore_index создает новый индекс financials.drop_duplicates(keep = ‘last’, subset = [‘month’], ignore_index = True, inplace = True) financials |
Неверные значения
Распространенным типом ошибок в данных являются неверные значения.
Базовый подход к поиску неверных значений — проверить, что данные не противоречат своей природе. Например, цена товара не может быть отрицательной.
В нашем случае мы видим, что в столбце MoM все строки отражают доли процента, а последняя строка — проценты. Из-за этого сильно искажается, например, средний показатель изменения выручки за год.
|
# рассчитаем среднемесячный рост financials.MoM.mean() |
С учетом имеющихся данных вряд ли среднее изменение выручки (в месячном, а не годовом выражении) составило 17,3%. Заменим проценты на доли процента.
|
# заменим 2% на 0.02 financials.iloc[11, 2] = 0.02 |
Вновь рассчитаем средний показатель.
Новое среднее значение 0,8% выглядит гораздо реалистичнее.
Форматирование значений
Тип str вместо float
Попробуем сложить данные о прибыли.
|
‘1.20$1.30$1.25$1.27$1.13$1.23$1.20$1.31$1.24$1.18$1.17$1.23$’ |
Так как столбец profit содержит тип str, произошло объединение (concatenation) строк. Преобразуем данные о прибыли в тип float.
|
# вначале удалим знак доллара с помощью метода .strip() financials[‘profit’] = financials[‘profit’].str.strip(‘$’) # затем воспользуемся знакомым нам методом .astype() financials[‘profit’] = financials[‘profit’].astype(‘float’) |
Проверим полученный результат с помощью нового для нас ключевого слова assert (по-англ. «утверждать»).
Если условие идущее после assert возвращает True, программа продолжает исполняться. В противном случае Питон выдает AssertionError.
Приведем пример.
|
# напишем простейшую функцию деления одного числа на другое def division(a, b): # если делитель равен нулю, Питон выдаст ошибку (текст ошибки указывать не обязательно) assert b != 0 , ‘На ноль делить нельзя’ return round(a / b, 2) |
|
# попробуем разделить 5 на 0 division(5, 0) |

Выражение
b != 0 превратилось в False и Питон выдал ошибку. Теперь вернемся к нашему коду.
|
# проверим превратился ли тип данных во float assert financials.profit.dtype == float |
Сообщения об ошибке не появилось, значит выражение верное (True). Теперь снова рассчитаем прибыль за год.
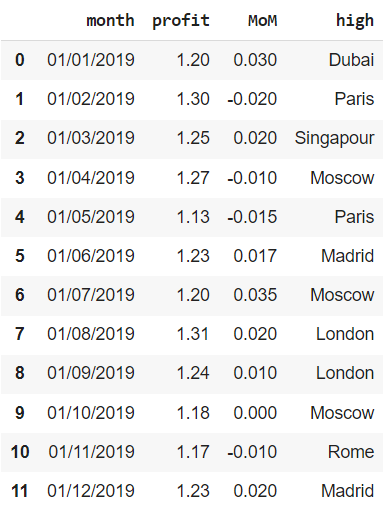
Названия городов с заглавной буквы
Остается сделать так, чтобы названия всех городов в столбце high начинались с заглавной буквы. Для этого подойдет метод .title().
|
financials[‘high’] = financials[‘high’].str.title() financials |
Дата и время
Как мы уже знаем, с датой и временем гораздо удобнее работать, когда они представляют собой объект datetime. В этом случае мы можем использовать все возможности Питона по анализу и прогнозированию временных рядов.
Начнем с того, что воспользуемся функцией pd.to_datetime(), которой передадим столбец month и формат, которого следует придерживаться при создании объекта datetime.
|
# запишем дату в формате datetime в столбец date1 financials[‘date1’] = pd.to_datetime(financials[‘month’], format = ‘%d/%m/%Y’) financials |

Мы получили верный результат. Как и должно быть в Pandas на первом месте в столбце date1 стоит год, затем месяц и наконец день. Теперь давайте попросим Питон самостоятельно определить формат даты.
|
# для этого подойдет параметр infer_datetime_format = True financials[‘date2’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True) financials |

У нас снова получилось создать объект datetime, однако возникла одна сложность. Функция pd.to_datetime() предположила, что в столбце month данные содержатся в американском формате (месяц/день/год), тогда как у нас они записаны в европейском (день/месяц/год). Из-за этого в столбце date2 мы получили первые 12 дней января, а не 12 месяцев 2019 года.
|
# исправить неточность с месяцем можно с помощью параметра dayfirst = True financials[‘date3’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True, dayfirst = True) financials |

Теперь мы снова получили верный формат.
|
# убедимся, что столбцы с датами имеют тип данных datetime financials.dtypes |
|
month object profit float64 MoM float64 high object date1 datetime64[ns] date2 datetime64[ns] date3 datetime64[ns] dtype: object |
Удалим избыточные столбцы и сделаем дату индексом.
|
financials.set_index(‘date3’, drop = True, inplace = True) # drop = True удаляет столбец date3 financials.drop(labels = [‘month’, ‘date1’, ‘date2’], axis = 1, inplace = True) financials.index.rename(‘month’, inplace = True) financials |
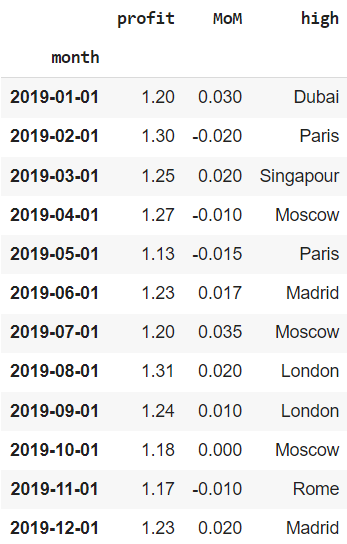
Посмотрим на еще один интересный инструмент. Предположим, что мы ошиблись с годом (вместо 2019 у нас на самом деле данные за 2020 год) или просто хотим создать индекс с датой с нуля. Для таких случаев подойдет функция pd.data_range().
|
# создадим последовательность из 12 месяцев, # передав начальный период (start), общее количество периодов (periods) # и день начала каждого периода (MS, т.е. month start) range = pd.date_range(start = ‘1/1/2020’, periods = 12, freq = ‘MS’) # сделаем эту последовательность индексом датафрейма financials.index = range financials |
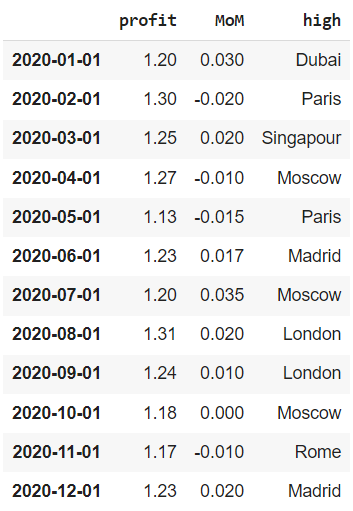
Как мы уже знаем, когда индекс имеет тип данных datetime, мы можем делать срезы по датам.
|
# напоминаю, что для datetime конечная дата входит в срез financials[‘2020-01’: ‘2020-06’] |

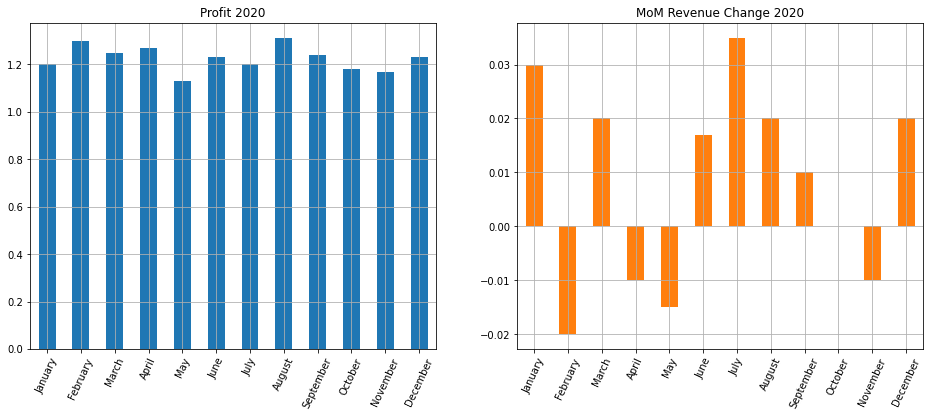
Завершим раздел про дату и время построением двух подграфиков. Для этого вначале преобразуем индекс из объекта datetime обратно в строковый формат с помощью метода .strftime().
|
# будем выводить только месяцы (%B), так как все показатели у нас за 2020 год financials.index = financials.index.strftime(‘%B’) financials |

Теперь используем метод .plot() библиотеки Pandas с параметром subplots = True.
|
# построим графики для размера прибыли и изменения выручки за месяц financials[[‘profit’, ‘MoM’]].plot(subplots = True, # обозначим, что хотим несколько подграфиков layout = (1,2), # зададим сетку kind = ‘bar’, # укажем тип диаграммы rot = 65, # повернем деления шкалы оси x grid = True, # добавим сетку figsize = (16, 6), # укажем размер figure legend = False, # уберем легенду title = [‘Profit 2020’, ‘MoM Revenue Change 2020’]); # добавим заголовки |
Подведем итог
Сегодня мы рассмотрели типичные ошибки в данных и способы их исправления. В частности, мы изучили как выявить и удалить дубликаты, обнаружить неверные значения и скорректировать неподходящий формат. Кроме того, мы еще раз обратились к объекту datetime и посмотрели на возможности изменения даты и времени.
Перейдем к работе с пропущенными значениями.

Опираясь на статистику легко лгать,
но без статистики очень трудно выяснить истину.
В любом научном исследовании главное — это полученные результаты. Однако, для того чтобы из них можно было сделать выводы, требуется статистическая обработка полученных данных.
Для тех, кто хорошо разбирается в математике, статистика не вызывает серьезных затруднений. Тем не менее разнообразные исследования показывают, что значительная доля научных публикаций содержит те или иные статистические ошибки. Об ошибках при переводе научных работ читайте в статье.
В. Джонсон из Техасского университета считает, что плохая статистика является одной из главных причин недостаточной воспроизводимости результатов в психологических исследованиях.
В этой статье мы расскажем о часто встречающихся ошибках статистического анализа и о том, как их избежать. С полезными сервисами для авторов можно ознакомиться здесь.
Содержание статьи
- 1. Сколько вешать в граммах?
- 2. Разбивка непрерывных данных на группы.
- 3. Среднее и сигмальное отклонение, медиана и доверительный интервал.
- 4. p-критерий.
- 5. Адекватность модели.
- 6. Понятие нормы.
- 7. Учет сомнительных и неопределенных результатов.
- 8. Понятие объекта исследования.
- 9. Статистическая значимость полученных результатов.
- 10. Влияние факторов риска.
- Заключение
1. Сколько вешать в граммах?
Любой ученый дорожит полученными результатами. Каждая цифра представляется нам достаточно значимой, чтобы представить ее в том виде, в котором она была получена. Получили вес 60,245 кг — так и запишем. Часто кажется, что, округляя данные, мы обесцениваем собственный труд.
Однако, с точки зрения читателя излишняя точность скорее мешает. Цифры с длинными хвостами трудно воспринимать и оценивать. Если их можно округлить без ущерба для точности выводов, нужно это сделать. Например, ни для каких целей нет смысла указывать вес взрослого человека с точностью до грамма.
Учитывайте при округлении точность приборов. Если весы дают погрешность более 100 граммов, указывать десятые доли килограмма не стоит.
При округлении процентов в научных статьях рекомендуется использовать следующие правила: если выборка больше 1 000, результат округляется до сотых; от 100 до 1 000 – до десятых; от 20 до 100 – до целых значений процентов. Для выборки менее 20, лучше дать абсолютные значения. В маленьких группах проценты скорее запутывают читателя и часто выглядят курьезно: в результате лечения 33, 333% животных выздоровели; 33, 333% погибли; третья мышь убежала.
Количество знаков после запятой должно быть одинаковым во всей статье. Если все результаты округляются до сотых, а какой-то из них имеет вид целого числа, то его нужно записать так же, как все остальные цифры, например 24,00.
2. Разбивка непрерывных данных на группы.
Такие данные, как рост, вес или возраст часто делят на категории. Разбивка упрощает статистический анализ, но в любом случае необходимо обосновать принципы, по которым это сделано.
Деление на категории может приводить к некорректным выводам. Например, если выборку разделили на пациентов с нормальной массой тела, дефицитом и избытком массы, то различия между людьми с весом 80 и 150 килограммов могут быть больше, чем между людьми с весом 70 и 80 килограммов, хотя в первом случае они входят в одну группу (с избытком массы), а во втором — в разные.
3. Среднее и сигмальное отклонение, медиана и доверительный интервал.
Представление в статье только средних групповых значений без учета индивидуальных различий может приводить к неверным выводам. Пресловутая средняя температура по больнице не дает представления не только обо всех пациентах, но даже о большинстве из них.
Средняя величина и среднее квадратическое отклонение или сигмальное отклонение δ (standard deviation — sd) описывают вариабельность выборки.
Среднее квадратическое отклонение применяется только в случае нормального распределения данных, то есть когда 68% показателей находятся в пределах ±1δ, 95% в пределах ±2δ, и 99% в пределах ±3δ.
При асимметричном распределении данных среднее квадратическое отклонение не дает правильного представления о выборке. В этом случае используется медиана median и межквартильный диапазон interquartile range (IQR) (как правило, от 25 до 75 центиля).
Точечные данные характеризуют такие показатели, как стандартная ошибка среднего и доверительный интервал.
Стандартная ошибка среднего standard error of the mean (m) показывает отличие фактических данных от значений, полученных на модели. Она позволяет оценить точность модели.
Доверительный интервал confidence interval (CI) демонстрирует, насколько выборка отражает свойства генеральной совокупности. В медицинских исследованиях обычно указывают 95% доверительный интервал.
Средняя величина, указанная без доверительного интервала, не дает полного и правильного представления о полученном эффекте. Например, если среднее снижение артериального давления 20 мм. рт. ст., эффект может показаться клинически значимым. Однако при 95% доверительном интервале от 5 до 30 мм. рт. ст. целесообразность применяемой схемы лечения уже представляется сомнительной, так как снижение показателя на 5 мм. рт. ст. клинически несущественно. Окончательный вывод о целесообразности изучаемой схемы лечения из этих результатов сделать нельзя.
Важно: в медицинских исследованиях результаты, подчиняющиеся нормальному распределению, встречаются довольно редко. Кроме того, средняя величина и среднее квадратическое отклонение плохо работают на малых выборках.
4. p-критерий.
Критерий р недостаточно информативен в медицинских и биологических исследованиях.
Дело в том, что статистическая значимость не равна клиническому значению и целесообразности использования тех или иных выводов на практике. Решение о рациональности использования препарата не может опираться только на статистическую значимость полученного клинического эффекта. Например, статистически значимое снижение артериального давления на 10 мм. рт. ст. клинически можно расценивать как отсутствие эффекта.
р-критерий не может равняться нулю. Это значило бы, что между группами есть действительно достоверное различие. Однако, такое различие невозможно установить методами статистики. Обычно эта ошибка связана с тем, что программы для статистической обработки данных приводят очень малые значения как р=0,00000. На самом деле это означает p<0,000001, что и должно быть указано в статье.
р-критерий не применяется к генеральной совокупности. Он показывает, что имеющиеся различия не являются случайностью и такой же результат может быть получен на другой выборке. В случае генеральной совокупности этот показатель не имеет смысла, так как речь о случайности различий не идет.
Если в исследовании участвует несколько групп, определение нескольких p-критериев повышает вероятность принять случайное совпадение фактов за причинно-следственную связь. Существует несколько методов решения проблемы множественных сравнений, их использование должно быть обосновано и описано.
В рандомизированных клинических исследованиях р-критерий указывать необязательно, так как исходные различия между группами всегда имеют место в силу случайности выбора.
5. Адекватность модели.
Регрессионные модели не работают, если зависимость между переменными не имеет линейного характера.
Чтобы подтвердить или опровергнуть линейный характер связи между величинами, нужно изучить остатки residuals, то есть отклонение реальных данных от линии регрессии, построенной на основании модели.
Регрессионная модель хорошо объясняет реальное положение дел, если остатки:
- независимы
- подчиняются нормальному распределению
- имеют нулевое среднее
- в их величинах нет тренда
Дисперсия остатков variance of the residuals показывает те изменения полученных данных, которые не объясняются моделью. Чем меньше дисперсия, тем лучше работает модель.
6. Понятие нормы.
Отсутствие четкого понимания, что следует принять за норму является серьезным недостатком клинических исследований.
Для определения нормы существует несколько подходов:
- результат говорит о наличии или отсутствии заболевания
- является показанием к назначению лечения
- указывает на риск развития болезни
- встречается у здоровых лиц
- укладывается в определенный диапазон значений
Далеко не во всех случаях норма клинически значима. Например, несовпадение индивидуальных сроков прорезывания зубов с нормальными, как правило, ни о чем не говорит.
Причины, по которым тот или иной показатель принят за норму, должны быть обоснованы.
7. Учет сомнительных и неопределенных результатов.
В медицинских и клинических исследованиях не всегда ясно, как учитываются сомнительные результаты при определении чувствительности и специфичности тестов. При наличии значительного процента сомнительных результатов практическая значимость выводов снижается.
Результат нельзя однозначно оценить как отрицательный или положительный если:
- получены пограничные значения показателя;
- интенсивность окрашивания препарата недостаточная;
- ответы на вопросы психологических тестов неоднозначные;
- нарушены стандарты при проведении исследования.
Если в статистический анализ включены не все результаты и не все участники исследования, возникают вопросы:
- Данные пропустили по ошибке или сознательно исключили из анализа, поскольку они противоречат первоначальной гипотезе и выводам?
- Не приведет ли исключение некоторых данных к тому, что результаты не будут воспроизводиться на другой выборке или при повторном исследовании?
- Если данные не были представлены полностью, то можно ли доверять другим фактам, содержащимся в статье?
Все это не украшает автора и снижает ценность его работы в глазах читателя и редактора журнала. Поэтому в статье нужно указать наличие и количество сомнительных и неопределенных результатов; пояснить, включались ли они в статистический анализ и как были интерпретированы.
8. Понятие объекта исследования.
Неверное определение объекта исследования может приводить к ошибкам и неточностям.
В клинических исследованиях объектом принято считать пациента. Когда в работе о методах лечения переломов единицей учета является не пациент, а сломанная кость, возникает вопрос, сколько больных участвовали в исследовании. Тем более непонятно, что означает 50% эффективность.
Если объектом исследования является язвенная болезнь, то размер выборки будет соответствовать количеству выявленных случаев заболевания, а не количеству обследованных пациентов.
В работах, основанных на заключениях специалистов, может быть необходимым исследовать выборку специалистов, а не общий массив заключений.
9. Статистическая значимость полученных результатов.
Статистическая значимость Statistical significance не равна клиническому значению.
При сравнении больших выборок статистически значимыми могут оказаться различия, не имеющие никакой реальной важности. Например, при среднем сроке службы приборов 5 лет различия на 1-2 недели клинического значения не имеют.
Наоборот, в малых выборках статистически незначимые различия могут быть важными клинически. Например, если в группе из нескольких больных в терминальном состоянии выжил хотя бы один, это безусловно клинически значимо.
10. Влияние факторов риска.
Истинное влияние фактора риска показывает относительный риск relative risk (RR) — отношение риска наступления исхода у подвергавшихся воздействию фактора к риску в контрольной группе. Этот показатель можно рассчитать, если группы набираются по принципу наличия и отсутствия фактора риска.
Если же группы набираются по принципу наличия или отсутствия исхода, то влияние можно оценить только приблизительно, используя показатель отношения шансов odds ratio (OR), описывающий силу связи между факторами.
Заключение
Главный вывод из сказанного: методы статистического анализа должны соответствовать характеру данных. Выбор тех или иных методов анализа нужно обосновать. Во избежание ошибок учтите:
- Характер распределения данных. Нормальное и асимметричное распределение требует разных подходов к анализу.
- Для анализа независимых выборок и парных данных (относящихся к одному и тому же участнику исследования) используются разные методы.
- Характер связи между переменными. Линейный характер связи позволяет использовать регрессионные модели. Чтобы подтвердить или опровергнуть линейную зависимость, нужно проанализировать остатки.
- В медицинских исследованиях клиническая значимость имеет приоритет над статистической.
- Норма должна быть клинически значимой; а выбор значения, принимаемого за норму, нужно обосновать.
- При наличии сомнительных или неопределенных результатов следует объяснить, как они учитываются в статистическом анализе.
- Объектом исследования следует считать человека или животное, а не болезнь и не клинический случай, так как два и более клинических случая могут иметь отношение к одному пациенту.
Статистические показатели в любом случае можно улучшить увеличением числа участников. По мнению В. Джонсона, принимая эталонное значение р-критерия в медицинских и биологических исследованиях на уровне <0.0005, можно существенно повысить качество статистики.
Часто ошибки статистического анализа вытекают из того, что эксперимент или исследование было изначально неправильно спланировано. В сомнительных случаях стоит обратиться к специалистам по статистике, однако делать это нужно на этапе подготовки, а не тогда, когда все работы уже завершены и возник вопрос, что же теперь делать с этими цифрами.
Современные программы для статистической обработки данных сильно облегчают вычисления, однако они не решают проблему выбора адекватных методов анализа и соответствия их характеру полученных данных. Поэтому залог успеха — тщательная подготовка исследования. Убедитесь, что материалы и методы, статистический анализ результатов и выводы соответствуют цели исследования.
Присоединяйтесь, чтобы моментально узнавать о новых статьях в нашем научном блоге, акциях и получать только полезные материалы!